



Reactive-Stream知识
本文最后更新于 2025-09-14,文章内容可能已经过时。
Reactive-Stream规范
传统的数据处理模式是生产者主动推送。如下图所示:
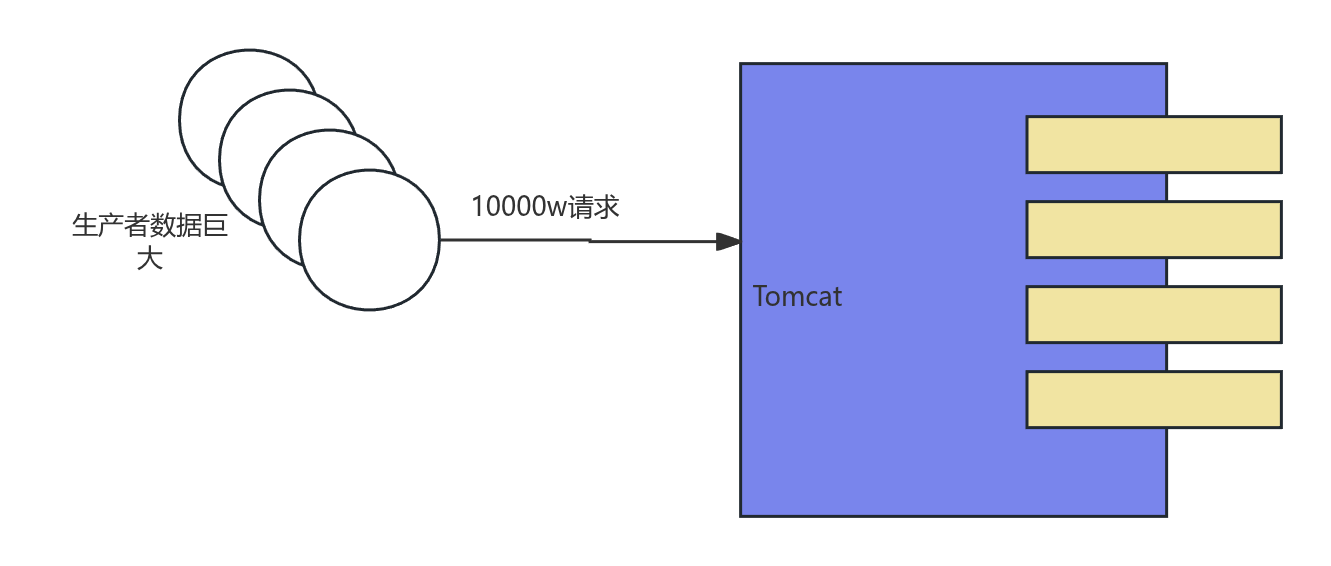
生产者(Producer):图左侧的“生产者”代表数据源。它拥有“巨大”或“大量”的数据,并以 10000w/s 的高速度源源不断地产生请求。
消费者(Consumer):图右侧的方框代表消费者,即处理这些数据的服务(例如图中的Tomcat和它后面的处理线程)。
在这种模式下,生产者不关心消费者的处理能力,而是以自己最快的速度将数据推送过去。这就像一个水龙头全开,而水管的承压能力有限。结果就是,消费者来不及处理所有请求,导致 “消费者压垮”。这种情况被称为 “正压”,即生产者对消费者施加了过大的压力。
这在现实中是常见的性能问题,例如:
消息队列的生产者发送过快,导致消费者消费不过来,堆积大量消息。
数据库连接池的请求量过大,超过了数据库的处理能力,导致连接耗尽或服务崩溃。
而Reactive-Stream所提倡的和这个不同,如下图所示:
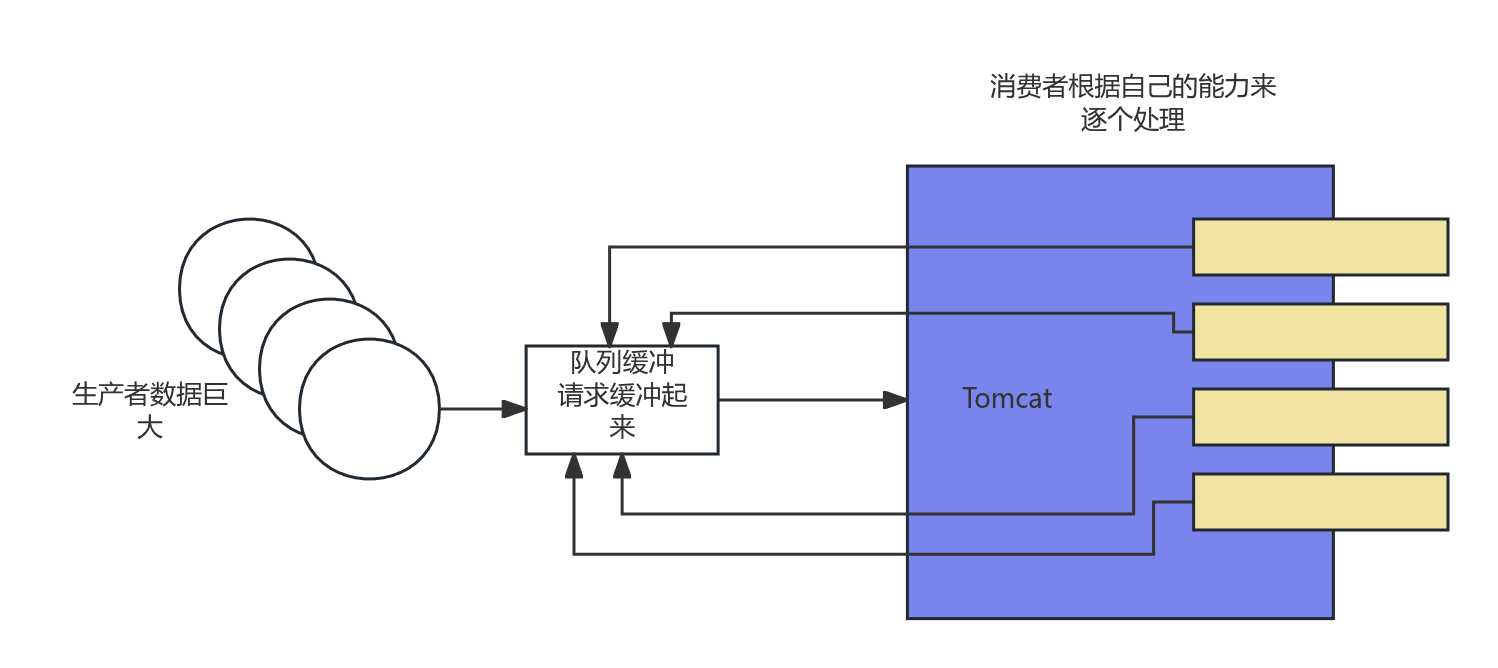
生产者(Producer):依然是大量数据的来源。
中间件(Queue):数据不再直接发送给消费者,而是先进入一个 队列(Queue),请求被 缓存(Buffer) 在这里。
消费者(Consumer):消费者 根据自己的能力(Tomcat 4核),主动从队列中 拉取(Pull) 数据进行处理。
这里的关键在于,消费者不再被动接收数据,而是主动向生产者(或者说中间的队列)发送请求,告知自己能够处理多少数据。
这就是 背压 的核心思想:消费者控制生产者的速度。当消费者处理不过来时,它会减少拉取的请求量,从而让生产者放慢速度,或者让数据在队列中暂存。这样就避免了消费者被海量数据压垮,实现了系统整体的稳定和弹性。
这个过程就像一个水龙头可以根据水池的容量来调整出水量,保证水池不会溢出。
那么是不是线程越多越好?还是越少越好?
关于线程的数量,答案并非简单的越多越好或越少越好,而是需要根据具体的应用场景和硬件环境来决定。
首先,线程不一定越多越好
如果系统中的线程数量过多,会带来以下问题:
过多的上下文切换(Context Switching):CPU 核心在不同线程之间来回切换时,需要保存当前线程的状态并加载下一个线程的状态。这个过程会消耗大量的 CPU 资源,导致真正用于执行任务的时间减少,系统性能反而下降。
内存消耗大:每个线程都需要一定的内存来存储栈空间、程序计数器等信息。如果线程数量过多,会占用大量的内存,可能导致内存溢出或频繁的垃圾回收,进一步影响系统性能。
竞争和死锁:线程越多,对共享资源的竞争就越激烈,需要更复杂的同步机制来保证数据一致性,这会增加开发和维护的复杂度,也更容易产生死锁。
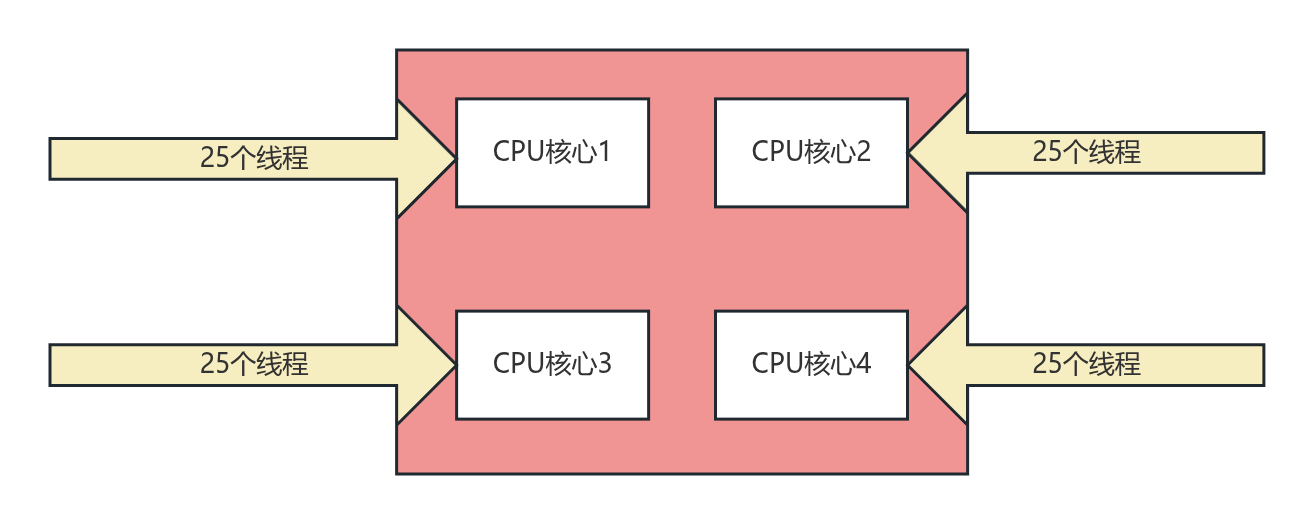
比如上图所示:当一个核心执行完一个线程后,它必须进行上下文切换(context switching)来执行下一个排队的线程。这个切换过程需要保存当前线程的状态,并加载新线程的状态,这个过程会浪费时间,并占用额外的内存(保留现场)。过多的线程导致激烈的竞争和频繁的上下文切换,反而降低了整体效率。这就像让一个车间同时处理 100 个订单,工人需要不断地切换任务,导致效率低下。
线程也不是越少越好
如果线程数量过少,则可能无法充分利用多核 CPU 的性能,导致资源浪费。例如,在一个 8 核的 CPU 上,如果只使用 1 个线程,那么其余 7 个核心将处于空闲状态,无法并行处理任务。
最佳实践是:让少量的线程一直忙,而不是让大量的线程一直切换等待。
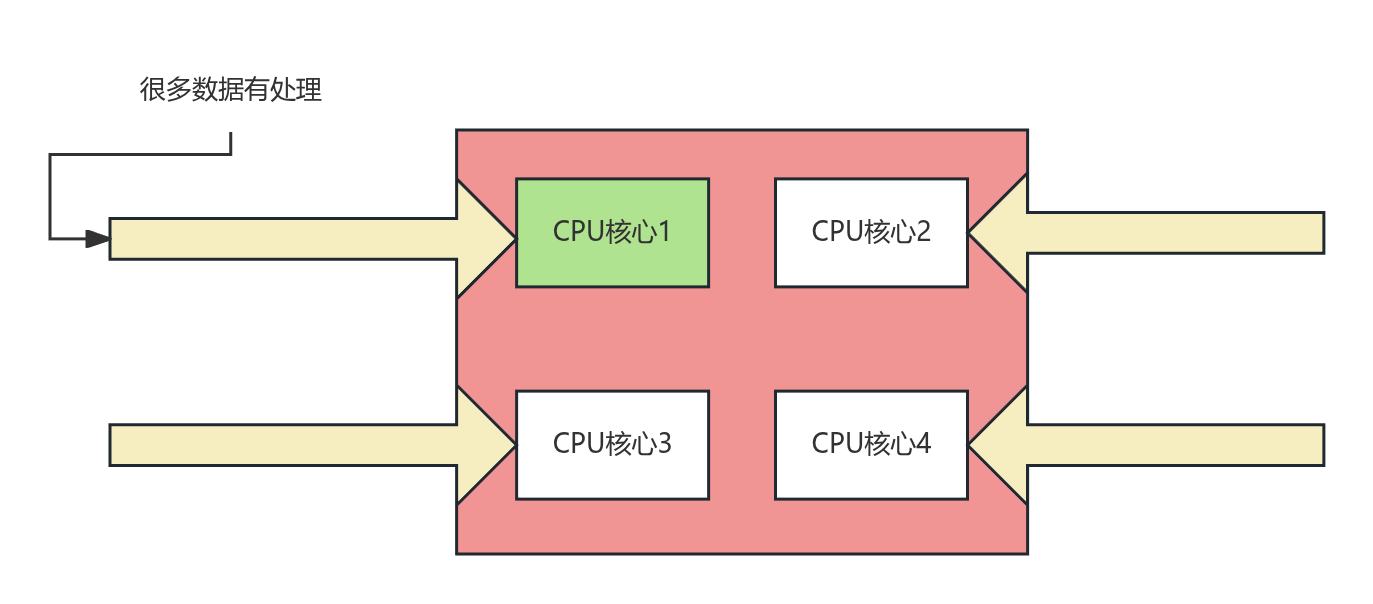
在这种模式下,线程的数量与 CPU 核心数相匹配。当有请求进来时,每个线程都可以独占一个 CPU 核心,持续地处理任务。没有多余的线程需要排队和切换,因此CPU 的利用率最高,系统性能最好。
总的来说,Reactive Streams 是一套关于异步数据流的规范,其核心目标是解决背压问题。它通过定义一套通用的接口(Publisher, Subscriber, etc.),使得不同的库能够互操作,并且提供了一种**消费者驱动(pull-based)**的流量控制机制,确保异步系统在高负载下的稳定性和可靠性。
这让构建高性能、可扩展的异步应用变得更加简单和安全。
Java9 Flow类
Java 9 引入的 java.util.concurrent.Flow 是 Reactive Streams 规范在 Java 标准库中的具体实现。
为什么 Java 9 要这么做?
在 Java 9 之前,如果你想使用 Reactive Streams,你必须依赖第三方库,比如 RxJava 或 Project Reactor。这些库虽然功能强大,但它们都各自有自己的实现,并且无法直接互操作。
为了解决这个问题,Reactive Streams 规范被制定出来,它定义了一套通用的接口。这样,不同的库就可以通过这套接口进行数据交换。
而 Java 9 的 Flow 类,正是将这套规范“官方化”了,将其直接内置到了 JDK 中。
Flow 类包含了什么?
Flow 类本身是一个静态类,它内部包含了 Reactive Streams 规范中的四个核心接口:
Flow.Publisher<T>:对应规范中的Publisher,数据生产者。Flow.Subscriber<T>:对应规范中的Subscriber,数据消费者。Flow.Subscription:对应规范中的Subscription,连接器和背压控制器。Flow.Processor<T, R>:对应规范中的Processor,既是订阅者又是发布者。
简单来说,Flow 类并没有提供任何具体的实现,它只是把 Reactive Streams 的接口定义搬到了 JDK 里。
先看第一幅图:

这个图就很好的展示了 背压(Backpressure) 的工作模式。
发布者(Publisher):数据源,负责生成数据。
消息队列/缓冲区(Buffer):一个临时存储区,用于存放发布者发出的数据。
订阅者(Subscriber):数据消费者,负责处理数据。
订阅关系(Subscription):这是连接发布者和订阅者的“通道”。这个通道是双向的,既用于数据的单向流动,也用于背压信号的反向流动。
水龙头:这是一个非常形象的比喻,代表着订阅者可以控制数据流的开关。
这张图的关键在于从订阅者到发布者的箭头,上面写着“给上游一个信号,让他可以发元素下来了:背压模式”。这正是 Reactive Streams 的精髓:订阅者可以告诉发布者自己能够处理多少数据。当订阅者的处理能力有限时,它会向发布者发送一个“慢一点”的信号,发布者收到这个信号后就会暂停或减缓数据发送,从而避免了缓冲区溢出和系统崩溃。
现在我们用 Flow 类来实现这一操作:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Flow;
public class BackpressureExample {
// 线程池,用于模拟异步操作
private static final ExecutorService executor = Executors.newFixedThreadPool(2);
// 模拟发布者
static class MyPublisher implements Flow.Publisher<Integer> {
private Flow.Subscriber<? super Integer> subscriber;
private int count = 0;
@Override
public void subscribe(Flow.Subscriber<? super Integer> subscriber) {
this.subscriber = subscriber;
// 订阅成功后,通知订阅者
subscriber.onSubscribe(new MySubscription());
}
// 模拟订阅关系,处理背压
private class MySubscription implements Flow.Subscription {
// 存储订阅者请求的数据量
private long requested = 0;
@Override
public void request(long n) {
// 订阅者请求了 n 个数据
requested += n;
System.out.println(" [发布者] 接收到订阅者请求:" + n + "个元素。当前累计请求量:" + requested);
// 异步发送数据
executor.submit(() -> {
while (requested > 0) {
try {
Thread.sleep(100); // 模拟数据生成的延迟
} catch (InterruptedException e) {
e.printStackTrace();
}
if (count < 10) { // 只发送10个数据
subscriber.onNext(count);
System.out.println("[发布者] 发送数据:" + count);
count++;
requested--; // 发送一个,请求量减1
} else {
// 数据发送完毕
subscriber.onComplete();
return;
}
}
});
}
@Override
public void cancel() {
// 订阅者取消订阅
System.out.println("[发布者] 订阅已取消。");
}
}
}
// 模拟订阅者
static class MySubscriber implements Flow.Subscriber<Integer> {
private Flow.Subscription subscription;
private int processedCount = 0;
@Override
public void onSubscribe(Flow.Subscription subscription) {
this.subscription = subscription;
System.out.println("[订阅者] 已订阅,请求1个元素。");
// 初始请求 1 个元素
subscription.request(1);
}
@Override
public void onNext(Integer item) {
System.out.println("[订阅者] 接收到数据:" + item);
processedCount++;
// 模拟“慢”处理过程
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(" [订阅者] 已处理完,再次请求1个元素。");
// 每处理完一个,再请求下一个
subscription.request(1);
}
@Override
public void onError(Throwable throwable) {
System.err.println("[订阅者] 发生错误:" + throwable.getMessage());
}
@Override
public void onComplete() {
System.out.println("[订阅者] 数据接收完毕,总共处理了 " + processedCount + " 个元素。");
executor.shutdown();
}
}
public static void main(String[] args) {
MyPublisher publisher = new MyPublisher();
MySubscriber subscriber = new MySubscriber();
// 订阅操作
publisher.subscribe(subscriber);
}
}注意一下,这里打印的日志可能是混乱的。多线程状态下都是这样的。这也是多线程的难点所在。
代码中,MyPublisher 和 MySubscriber 都在不同的线程中执行。
MyPublisher的request()方法内部,数据发送(subscriber.onNext(count))是在一个独立的线程中进行的 (executor.submit(...))。MySubscriber的onNext()方法内部,数据处理(Thread.sleep(500))和再次请求(subscription.request(1))是在发布者发送数据过来的线程中执行的。
由于这两个部分(数据发送和数据处理/请求)在不同的线程中,操作系统会随机地调度这些线程的执行。这导致了日志的交错打印,你看到的输出顺序并不能反映代码的真实执行顺序。
例如,你可能看到的日志 [发布者] 发送数据:0 可能是在 [订阅者] 接收到数据:0 之后才被打印出来的,尽管从逻辑上讲,发送行为肯定发生在接收行为之前。
这段代码也好的展示了什么叫做消费者驱动,而非生产者驱动:
我们模拟的这个过程正是 Reactive Streams 的核心思想:消费者驱动(Pull-Based)。
传统的异步处理模式,比如一个简单的生产者-消费者队列,通常是**生产者驱动(Push-Based)**的。生产者会尽可能快地将数据推送到队列里,而不管消费者的处理能力如何。这就像一个水管,水龙头一直开着,下游的处理池子很快就会溢出来。
而 Reactive Streams 正好相反,它采用了 消费者驱动 的模式。它不是生产者在“推”数据,而是消费者在“拉”数据。
用我们代码中的例子来说明:
初始阶段:
MySubscriber(消费者)向MyPublisher(生产者)发送一个信号:“给我 1 个元素。”这个信号就是
subscription.request(1)。
数据传输:
MyPublisher接收到请求后,才开始发送数据。它会发送onNext(0)。因为
MySubscriber只请求了 1 个,MyPublisher在发送完这 1 个之后就会停下来,等待下一个请求。
流量控制:
MySubscriber在处理完这个元素后,再次发送信号:“我又可以处理 1 个了,再给我 1 个。”这个信号同样是
subscription.request(1)。
这个“拉”的过程,确保了数据发送的速率永远不会超过消费者的处理能力。消费者就是那个水龙头,它决定了数据流的大小和速度。
当然我们可以在中间加入多个处理环节,对数据进行处理加工:
package com.hanserwei.flow;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Flow;
import java.util.concurrent.SubmissionPublisher;
import java.util.function.Function;
public class PipelineExample {
private static final ExecutorService executor = Executors.newFixedThreadPool(4);
// --- 1. 模拟一个通用的 Processor ---
static class MyProcessor<T, R> extends SubmissionPublisher<R> implements Flow.Processor<T, R> {
private Flow.Subscription upstreamSubscription;
private final Function<T, R> transform;
// 构造函数,传入一个数据转换函数
public MyProcessor(Function<T, R> transform) {
this.transform = transform;
}
// Subscriber 的 onSubscribe 方法:接收上游订阅关系
@Override
public void onSubscribe(Flow.Subscription upstreamSubscription) {
this.upstreamSubscription = upstreamSubscription;
// 向上传递背压请求,初始请求1个
upstreamSubscription.request(1);
}
// Subscriber 的 onNext 方法:接收上游数据并处理
@Override
public void onNext(T item) {
executor.submit(() -> {
try {
// 模拟处理耗时
Thread.sleep(100);
System.out.println("[Processor] 接收到数据: " + item + ",进行转换...");
// 数据转换
R transformedItem = transform.apply(item);
// 将处理后的数据发送给下游
submit(transformedItem);
// 处理完一个,向上传递背压信号,请求下一个
upstreamSubscription.request(1);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
}
// 其他方法传递给下游
@Override
public void onError(Throwable throwable) {
throwable.printStackTrace();
closeExceptionally(throwable);
}
@Override
public void onComplete() {
System.out.println("[Processor] 数据处理完毕。");
close();
}
}
// --- 2. 模拟发布者和订阅者 ---
static class MyPublisher implements Flow.Publisher<Integer> {
private Flow.Subscriber<? super Integer> subscriber;
private int count = 0;
@Override
public void subscribe(Flow.Subscriber<? super Integer> subscriber) {
this.subscriber = subscriber;
subscriber.onSubscribe(new Flow.Subscription() {
@Override
public void request(long n) {
executor.submit(() -> {
for (int i = 0; i < n && count < 10; i++) {
System.out.println("[Publisher] 正在发送数据:" + count);
subscriber.onNext(count++);
}
if (count >= 10) {
subscriber.onComplete();
}
});
}
@Override
public void cancel() {}
});
}
}
static class MySubscriber implements Flow.Subscriber<String> {
private Flow.Subscription subscription;
@Override
public void onSubscribe(Flow.Subscription subscription) {
this.subscription = subscription;
System.out.println("[Subscriber] 已订阅,开始请求数据。");
subscription.request(1); // 初始请求1个
}
@Override
public void onNext(String item) {
System.out.println("[Subscriber] 接收到最终结果: " + item);
subscription.request(1); // 每处理一个,请求下一个
}
@Override
public void onError(Throwable throwable) {
System.err.println("[Subscriber] 发生错误: " + throwable.getMessage());
}
@Override
public void onComplete() {
System.out.println("[Subscriber] 数据流完成。");
executor.shutdown();
}
}
// --- 3. 组装数据流管道 ---
public static void main(String[] args) throws InterruptedException {
// 创建发布者和订阅者
MyPublisher publisher = new MyPublisher();
MySubscriber subscriber = new MySubscriber();
// 创建两个处理器
MyProcessor<Integer, Double> processor1 = new MyProcessor<>(i -> i * 1.5); // 乘以1.5
MyProcessor<Double, String> processor2 = new MyProcessor<>(d -> "结果: " + d); // 转换为字符串
// 管道组装:将它们链式连接起来
publisher.subscribe(processor1);
processor1.subscribe(processor2);
processor2.subscribe(subscriber);
// 等待处理完成
Thread.sleep(50000);
}
}我这里特别说一下这个线程池的目的是啥,这里使用线程池的目的是为了模拟异步和非阻塞
回顾一下代码中的两个主要使用场景:
在
Publisher中发送数据:executor.submit(() -> { ... onNext(...) })我们没有在request()方法的线程中直接调用onNext()来发送数据。相反,我们把发送数据的任务提交到了线程池。这模拟了在一个真实的系统中,数据可能来自于一个缓慢的 I/O 操作(比如网络请求、文件读取),这些操作是异步完成的。通过使用线程池,request()方法可以立即返回,不会因为等待数据生成而阻塞调用线程。在
Processor中处理数据:executor.submit(() -> { ... transform(...) ... })Processor接收到上游数据后,同样没有在接收数据的线程中直接进行耗时的数据转换。它将转换任务提交到了线程池。这模拟了数据处理本身可能是一个耗时的操作(例如复杂的计算或数据库查询)。这确保了onNext()方法能快速返回,不会阻塞上游数据流。
通过这种方式,我们的代码遵循了 Reactive Streams 的设计原则,即:数据流是异步的,并且不应阻塞。这使得整个系统在处理大量数据流时能够保持高效和响应。


