Kafka常见面试题
本文最后更新于 2025-12-27,文章内容可能已经过时。
Kafka常见面试题
如何保证Kafka消息不丢失
和RabbitMQ相似,在Kafka里面如果有防止消息不丢失,还是从以下3个方面入手解决。
-
防止生产者发送消息到Broker导致的消息丢失
-
设置异步发送
// 同步发送 RecordMetadata recordMetadata = kafkaProducer.send(record).get(); // 异步发送 kafkaProducer.send(record, new Callback() { @Override public void onCompletion(RecordMetadata recordMetadata, Exception e) { if (e != null) { System.out.println("消息发送失败 | 记录日志"); } long offset = recordMetadata.offset(); int partition = recordMetadata.partition(); String topic = recordMetadata.topic(); } });如果消息成功发送,那么回调里面就不会有异常,如果出现了异常,那么就可以在回调函数里面进行兜底操作。
-
如果是由于网络波动,也可以利用kafka自己的重试机制
// 设置重试次数 prop.put(ProducerConfig.RETRIES_CONFIG, 10);
-
-
在Broker中解决消息不丢失
- 发送确认机制ACK
确认机制 说明 acks=0 生产者在成功写入消息之前不会等待任何来自服务器的响应,消息有丢失的风险,但是速度最快 acks=1(默认值) 只要集群首领节点收到消息,生产者就会收到一个来自服务器的成功响应 acks=all 只有当所有参与赋值的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应
- 发送确认机制ACK
-
消费者冲Broker接受消息防止消息丢失
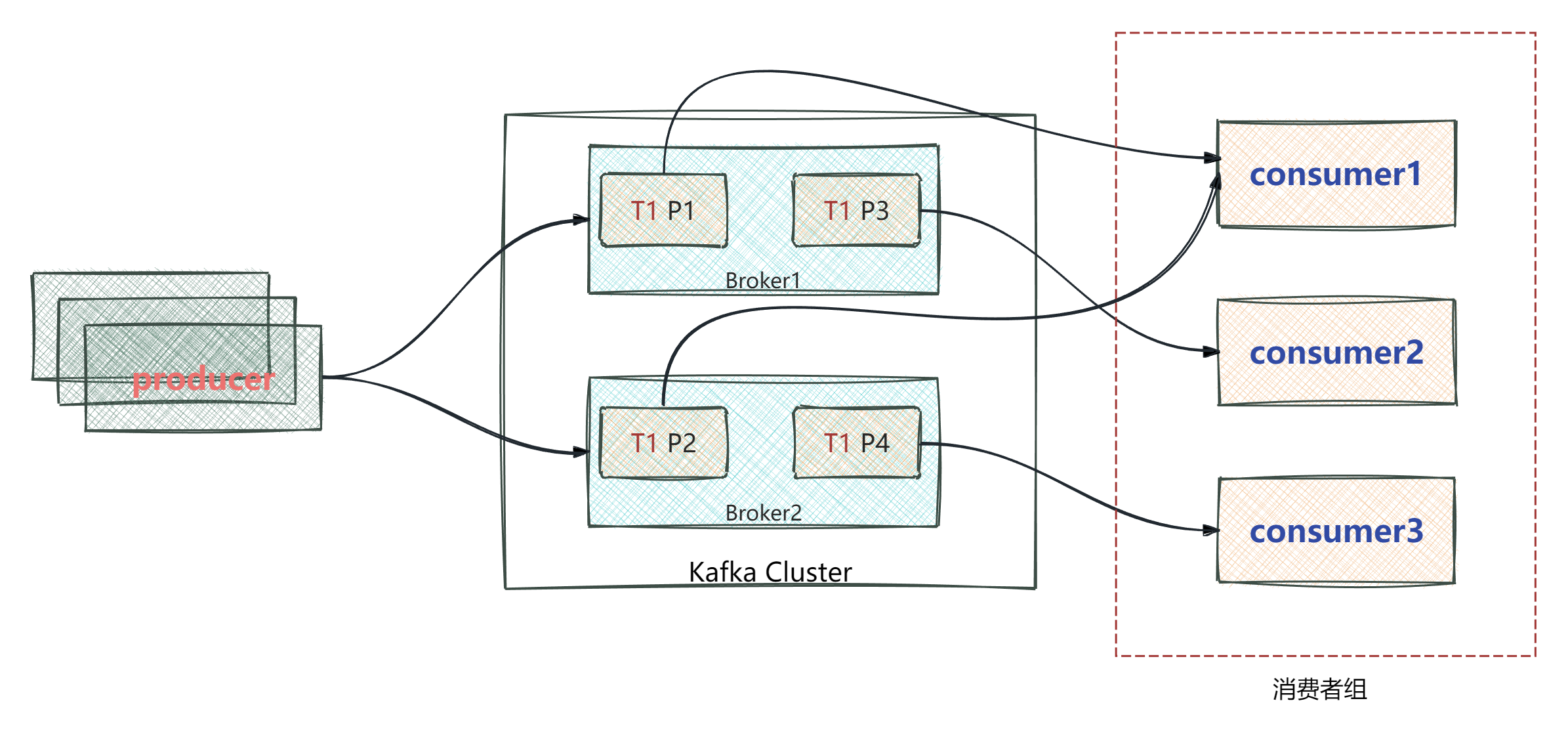
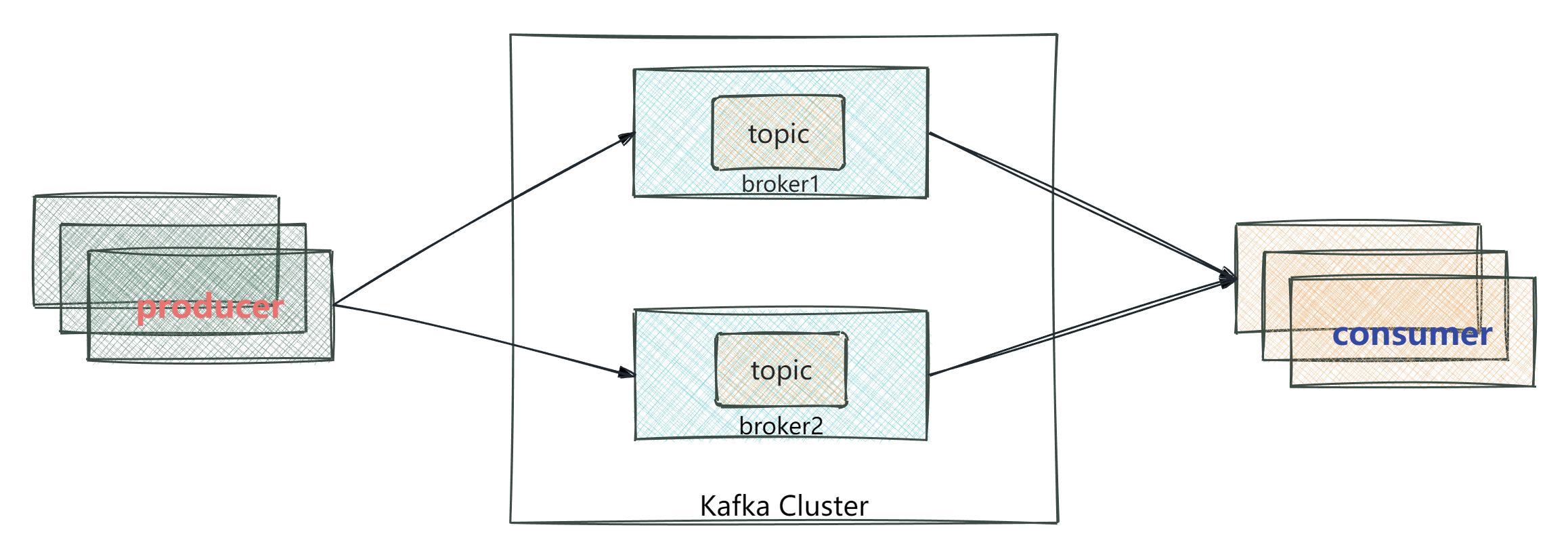
- Kafka中的分区机制是将每个主题划分为多个分区(Partition)
- topic分区中的消息只能由消费者组中的唯一一个消费者处理,不同的分区分配给不同的消费者(同一个消费组)
- 不同的分区是按偏移量来存储消息的
如图:
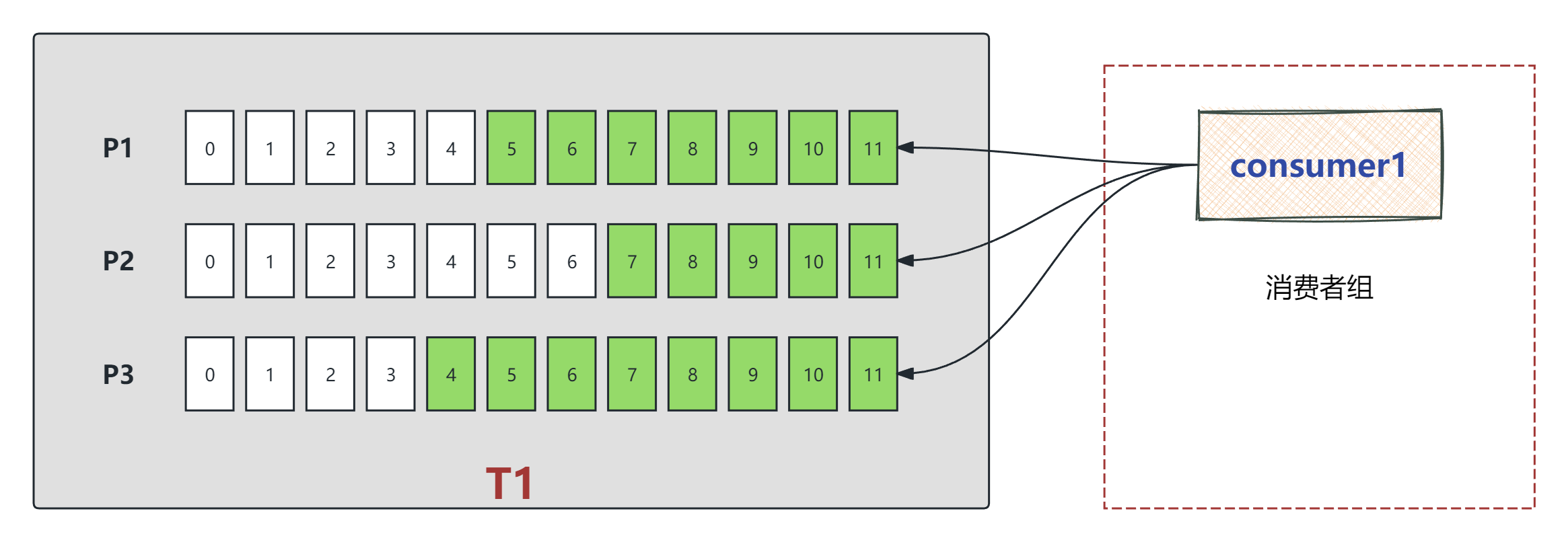
在 Kafka 消费过程中,由于定期自动提交(
enable.auto.commit=true)是基于固定时间间隔执行的,它与实际消息处理的进度并不同步,这正是导致消息丢失或重复消费的根本原因。-
为什么会导致消息丢失?
消息丢失通常发生在**“先提交,后处理失败”**的情况下。
原理: 假设你设置每 5 秒自动提交一次。在第 3 秒时,消费者拉取了一批消息(如偏移量 5-10)。
触发丢失: 刚好在第 5 秒,Kafka 客户端自动将偏移量 10 提交到了服务端。然而,此时你的业务代码可能刚处理完偏移量 7,在处理偏移量 8 时程序崩溃(Crash)或重启。
后果: 当消费者恢复后,它会从上次提交的偏移量 10 开始拉取。这意味着 8、9、10 这几条消息虽然从未被成功处理,但在 Kafka 看来已经“消费完成”了,从而导致消息丢失。
-
为什么会导致重复消费?
重复消费通常发生在**“已处理,未提交”**的情况下。
原理: 同样假设 5 秒提交一次。消费者拉取了偏移量 5-10 的消息。
触发重复: 在第 4 秒时,你的业务代码已经成功处理了所有消息(5-10)。但在第 5 秒自动提交动作发生之前,消费者突然断开连接或触发了再均衡(Rebalance)。
后果: 由于偏移量 10 还没来得及提交,Kafka 服务端记录的最新偏移量仍是 5。当新的消费者接管该分区(如图片中的 P1、P2 或 P3)后,它会再次从偏移量 5 开始拉取,导致 5-10 的消息被业务系统重新处理一遍。
-
解决办法:
- 禁用自动提交偏移量,改为手动,采用异步和同步提交的组合。
try { while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000)); for (ConsumerRecord<String, String> record : records) { System.out.println(record.value()); System.out.println(record.key()); } // 异步提交:在循环中为了效率使用异步提交 consumer.commitAsync(); } } catch (Exception e) { e.printStackTrace(); System.out.println("记录错误信息: " + e); } finally { try { // 同步提交:在消费者关闭前,确保最后一次偏移量提交成功 consumer.commitSync(); } finally { consumer.close(); } }
Kafka保证消息顺序性
应用场景:
- 即时单对单聊天和群聊,保证发送方消息发送顺序和接受方的顺序是一致的
- 充值转账两个渠道在同一个时间进行余额变更,短信通知必须有顺序
topic分区中消息只能由消费者组中的唯一一个处理,所以消息肯定是按照先后顺序进行处理的。但是它仅仅是保证Topic的一个分区顺序处理,不能保证跨分区的消息先后处理顺序。所以,如果需要顺序处理Topic的所有消息,那就只能提供一个分区。
// 指定分区发送
kafkaTemplate.send("springboot-kafka-topic", 0, "key-001", "value-0001");
// 使用相同的业务key发送
kafkaTemplate.send("springboot-kafka-topic", "key-001", "value-0001");
在 Kafka 中,如果你没有在发送时手动指定分区号(即上面代码的第一种方式),Kafka 会使用 分区策略(Partitioner) 来决定消息去往哪个分区。
当消息包含 Key 时,Kafka 默认的分区器会执行以下操作:
- 计算哈希值:对 Key(如
"key-001")进行哈希运算(通常是murmur2算法)。 - 取模运算:用计算出的哈希值对该 Topic 的分区总数进行取模。
- 公式: partition = hash(key) \pmod{numPartitions}
Kafka高可用机制
- 集群模式
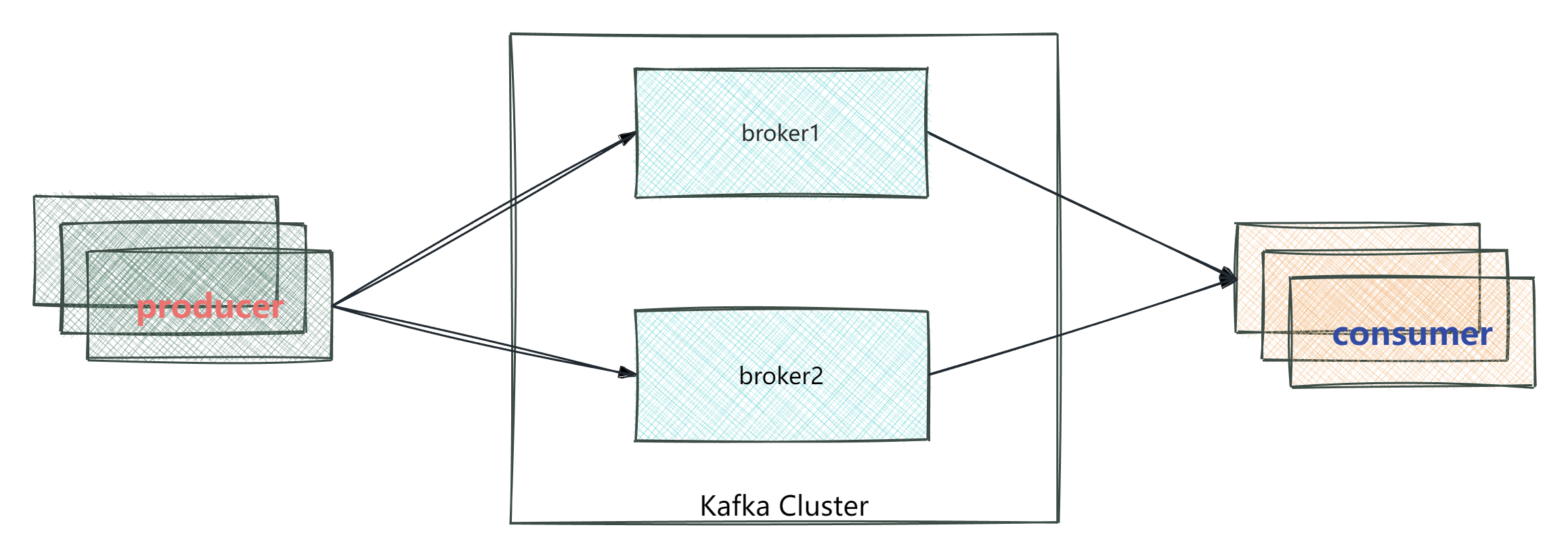
- Kafka的服务器端由被称为Broker的服务进程构成,即一个Kafka集群由多个Broker组成
- 这样如果集群中某一台机器岩机,其他机器上的Broker也依然能够对外提供服务。这其实就是Kafka提供高可用的手段之一
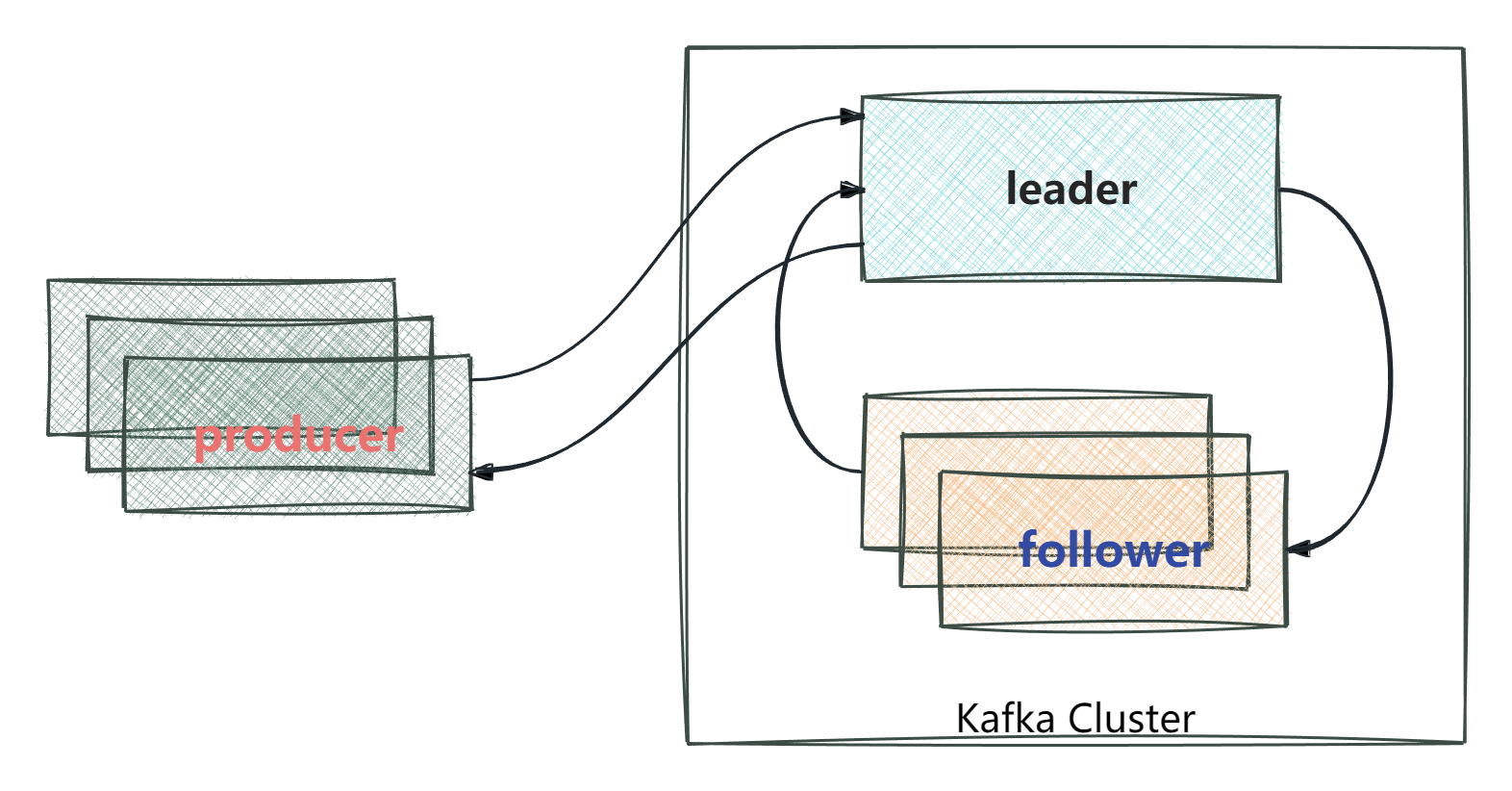
分区备份机制
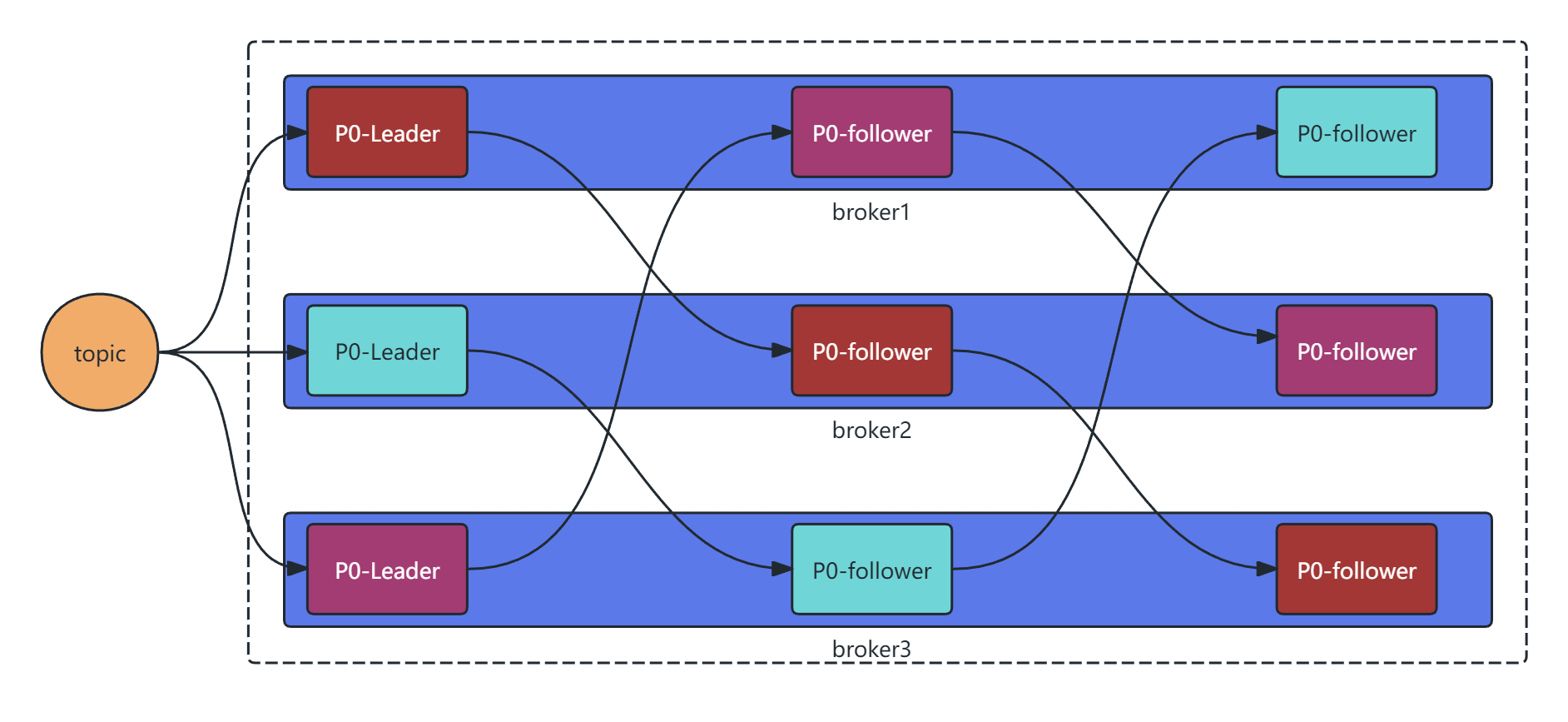
某一个topic中有三个分区P0、P1、P2
- 一个topic有多个分区,每个分区有多个副本,其中有一个leader,其余的是follower,副本存储在不同的broker中
- 所有的分区副本的内容是都是相同的,如果leader发生故障时,会自动将其中一个follower提升为leader
当producer发送消息的时候,Leader分区会往ISR分区和普通分区发送消息,如图所示:
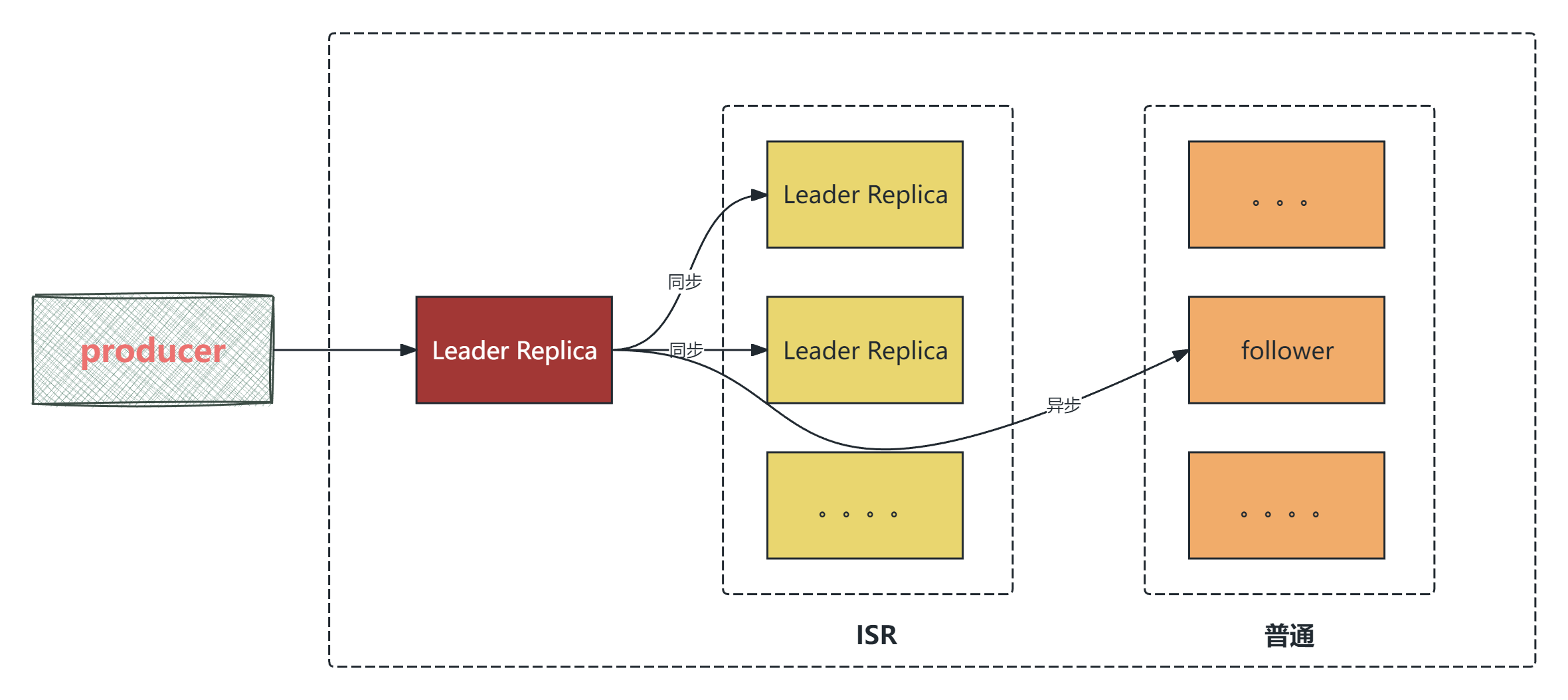
ISR (in-sync replica) 需要同步复制保存的follower
如果leader失效后,需要选出新的leader,选举的原则如下:
- 第一: 选举时优先从ISR中选定,因为这个列表中follower的数据是与leader同步的
- 第二: 如果ISR列表中的follower都不行了,就只能从其他follower中选取
//一个topic默认分区的replication个数,不能大于集群中broker的个数。默认为1
default.replication.factor=3
//最小的ISR副本个数
min.insync.replicas=2
Kafka数据清理机制
Kafka文件存储机制
存储结构:
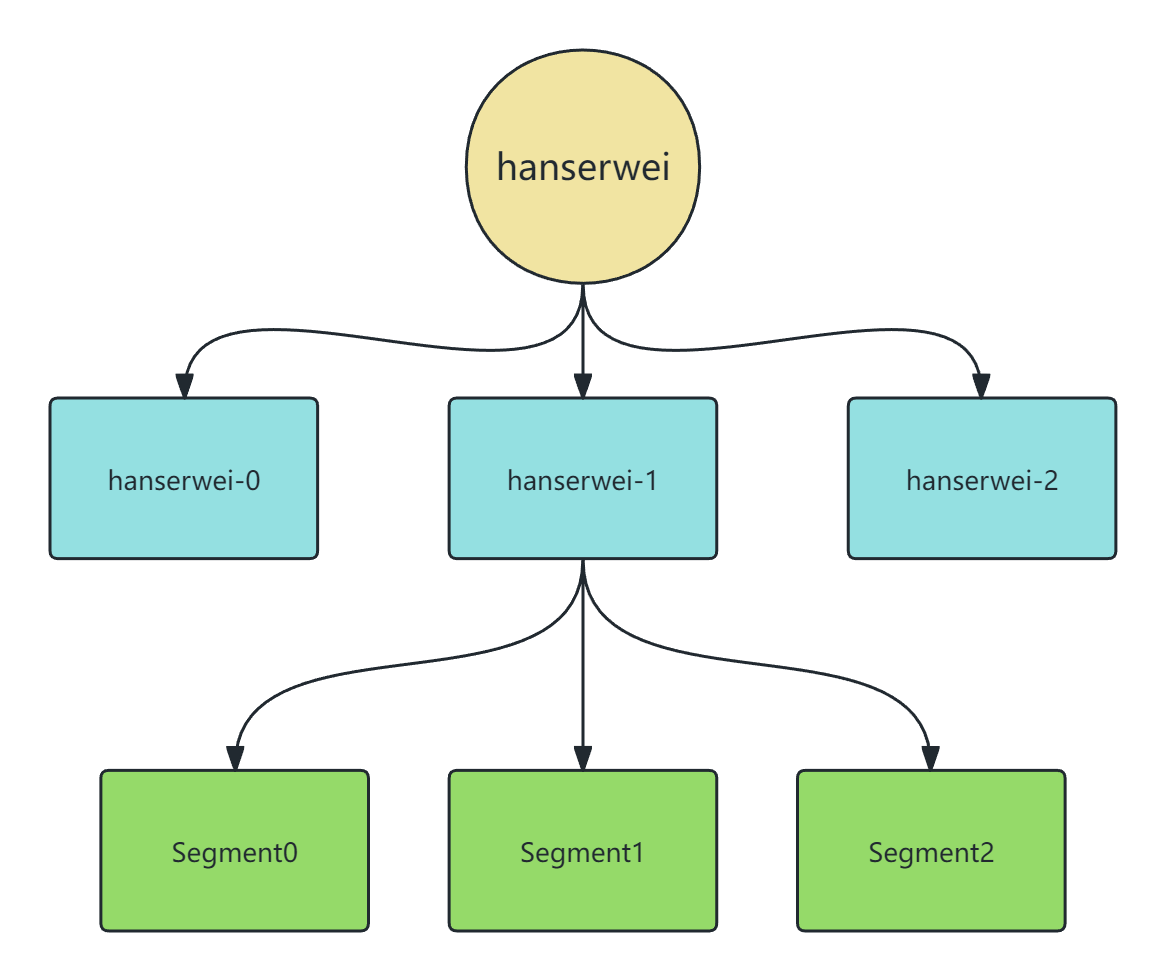
Kafka 的数据存储遵循“由大到小”的逻辑拆分,确保了系统的高伸缩性和读写效率:
- Topic(主题层): 如图中顶层的
hanserwei。这是一个逻辑上的分类。 - Partition(分区层): 一个 Topic 可以分为多个 Partition(如
hanserwei-0,hanserwei-1,hanserwei-2)。在物理磁盘上,每个 Partition 对应一个单独的文件夹。 - Segment(日志分段层): 每个 Partition 文件夹下又被切分为多个 Segment(如
Segment 0,Segment 1)。
为什么要引入 Segment(分段机制)?
根据图中的描述,将 Partition 进一步切分为 Segment 主要有两个核心目的:
- 删除无用文件方便,提高磁盘利用率: Kafka 的数据是有过期时间的。通过分段,可以更轻松地删除旧的 Segment 文件,而不会影响正在写入的活跃文件。
- 查找数据便捷: 较小的文件配合索引,可以大幅提高定位特定偏移量(Offset)数据的速度。
Segment 的物理组成
每个 Segment 并不是单一的文件,而是由一组具有相同文件名的不同后缀文件组成:
| 文件后缀 | 名称 | 作用 |
|---|---|---|
| .log | 数据文件 | 实际存储消息内容的地方。 |
| .index | 索引文件 | 偏移量索引,帮助快速根据 Offset 找到对应的消息在 .log 中的物理位置。 |
| .timeindex | 时间索引文件 | 根据时间戳查找消息位置的索引文件。 |
数据清理机制
日志的清理策略有两个
1. 根据消息的保留时间
当消息在 Kafka 中保存的时间超过了指定的时间,就会触发清理过程。
# The minimum age of a log file to be eligible for deletion due to age
# 默认保留时间(示例为 168 小时,即 7 天)
log.retention.hours=168
2.根据 Topic 存储的数据大小
当 Topic 所占的日志文件大小大于一定的阈值,则开始删除最久的消息。需手动开启。
# A size-based retention policy for logs. Segments are pruned from the log
# unless the remaining segments drop below log.retention.bytes.
# Functions independently of log.retention.hours.
# 示例阈值为 1073741824 字节(即 1GB)
#log.retention.bytes=1073741824
Kafka为什么快
消息分区(Partitioning)
- 提取: 不受单台服务器的限制,可以不受限的处理更多的数据。
- 补充: 分区是 Kafka 横向扩展(Scalability) 的基础。通过将一个 Topic 分成多个 Partition 分布在不同的 Broker(服务器)上,实现了并发读写。这也是负载均衡的关键。
顺序读写(Sequential I/O)
- 提取: 磁盘顺序读写,提升读写效率。
- 补充: 磁盘随机读写速度很慢,但顺序读写的性能接近内存。Kafka 采用 Append-only(只追加) 模式写入日志文件,避免了磁盘机械臂的频繁寻道,极大地提升了 I/O 吞吐。
页缓存(Page Cache)
- 提取: 把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问。
- 补充: Kafka 并不在 JVM 堆内存中缓存数据,而是利用 操作系统层面的 Page Cache。这样做避免了 JVM GC(垃圾回收)带来的性能开销,即使服务重启,缓存依然存在。
零拷贝(Zero Copy)
- 提取: 减少上下文切换及数据拷贝。
- 补充: 主要通过 Linux 的
sendfile系统调用实现。数据直接从“页缓存”传输到“网卡接口”,无需经过“用户态”内存,减少了 CPU 在内核态与用户态之间的切换次数。
消息压缩(Message Compression)
- 提取: 减少磁盘 IO 和网络 IO。
- 补充: 支持 Snappy、Gzip、LZ4 和 Zstd 等算法。压缩通常在生产者端完成,在消费者端解压,能显著降低网络带宽占用并节省磁盘存储空间。
分批发送(Batching)
- 提取: 将消息打包批量发送,减少网络开销。
- 补充: 通过攒够一定数量的消息或达到设定时间后再统一发送,大幅减少了网络请求的次数(RTT)和 TCP 报文头的比例,提高了整体的有效载荷。
零拷贝
如果不使用零拷贝技术,那么Kafka发送一条消息的过程如下:
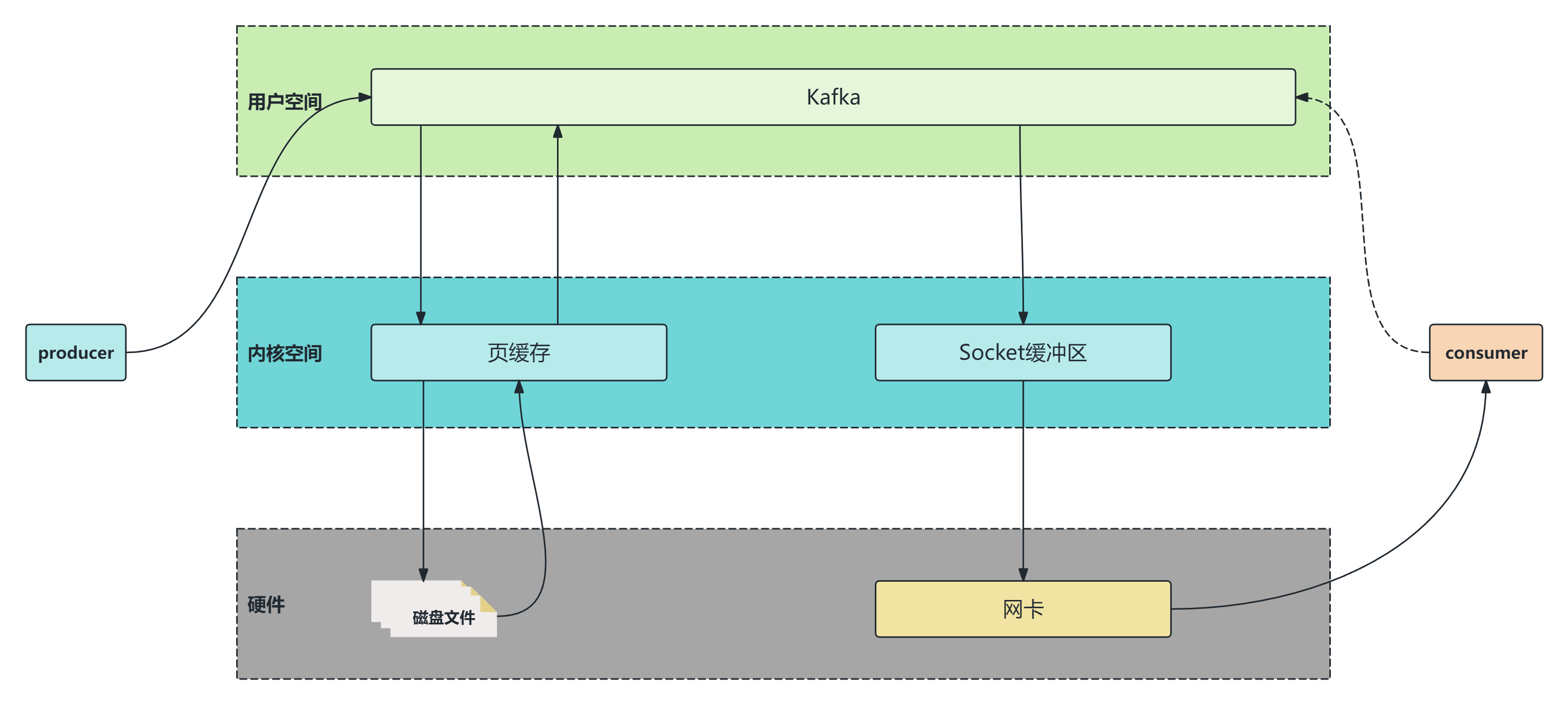
拷贝次数:磁盘文件-->页缓存-->Kafka-->Socket缓存区-->网卡,一共四次拷贝
如果使用零拷贝,那么流程如下:
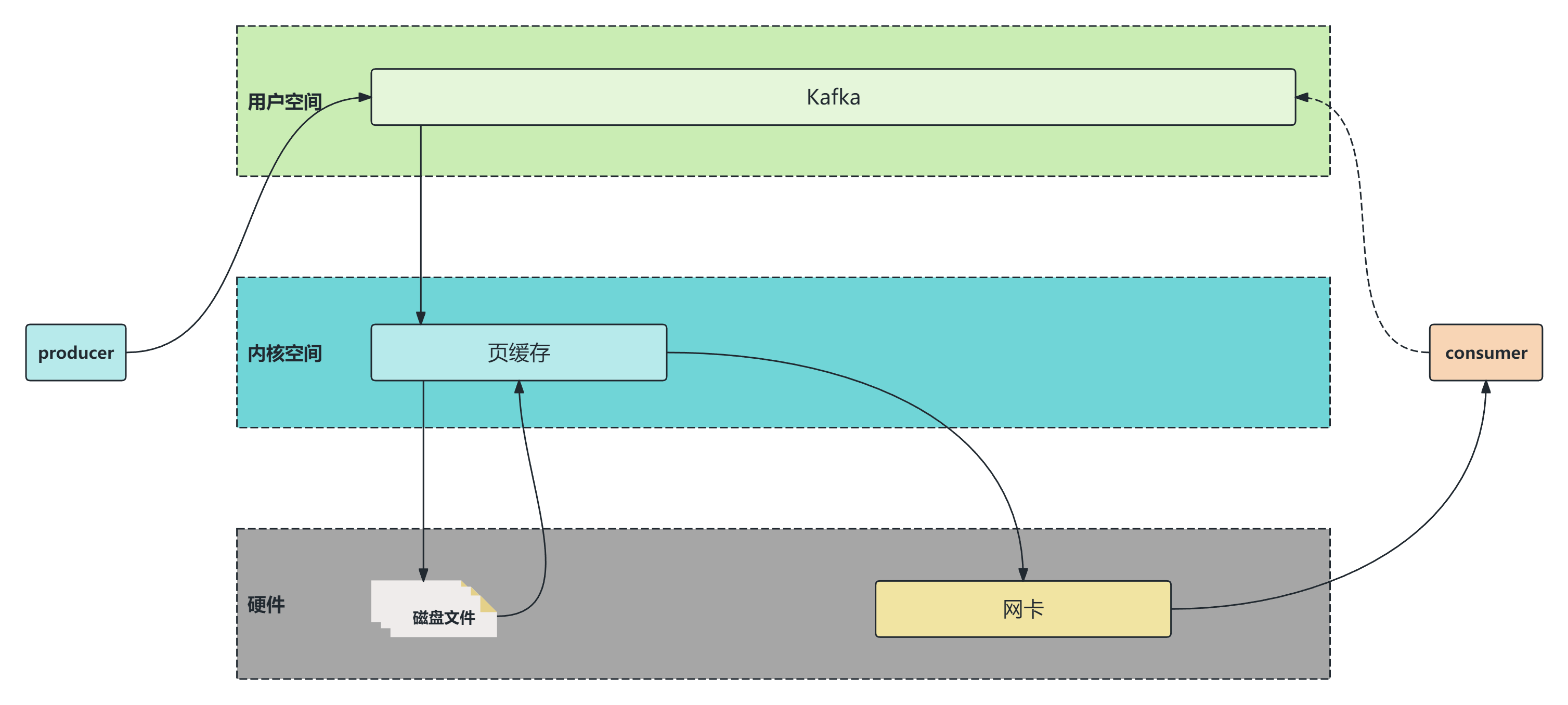
拷贝次数:磁盘文件-->页缓存-->网卡,就只需要两次拷贝即可。